
Chapter 6: PowerPoint PPT Presentation
Title: Chapter 6:
1
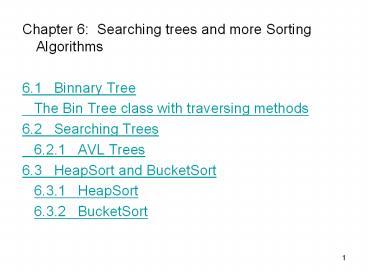
- Chapter 6 Searching trees and more Sorting
Algorithms - 6.1 Binnary Tree
- The Bin Tree class with traversing methods
- 6.2 Searching Trees
- 6.2.1 AVL Trees
- 6.3 HeapSort and BucketSort
- 6.3.1 HeapSort
- 6.3.2 BucketSort
2
Addendum A Webseite with animations for
AVL-trees http//www.seanet.com/users/arsen/
avltree.html A Webseite with animation for
Heapsort http//ciips.ee.uwa.edu.au/morris/
Year2/PLDS210/heapsort.html
3
b
First rotation
a
c
W
Z
x
y
new
a
Second rotation
b
W
c
x
new
y
Z
4
6.3 BucketSort
- All sorting procedures we have seen so far are
based on the comparission of two keys - The general bottom bound for the cost for this
kind of procedures is - O(n log n).
- For certain sets of keys
- Sorting without comparing keys and more efficient
!
5
Idea use the keys to calculate the the storing
addresses for the elements of the sequence to be
sorted (like in Hashing).
- Example (ideal situation, not frequent)
- Set of n data objects s0, ... , sn-1 with key
values 0, ..., n-1, without duplicates given as
an array S. - Sorting algoritm
- for(int i 0, i lt n, i)
- TSi.key Si
- cost O(n).
6
BucketSort
- Sets of n data objects s0, ... , s n-1 with key
values 0, ..., m-1, given as array S. - duplicate keys are allowed.
- void BucketSort(S)
- int i int j
- for(j0 jltm j)
- Bj null //the buckets, lists
- for(i0 iltn i)
- insert(Si, BSi.key() )
- for(j0 jltm j) output(Bj)
- cost O(nm).
7
RadixSort
- Sets of n data objects s0, ... , sn-1 with key
values - 0, ..., nk -1, given as an array S. Duplicate
keys allowed. - The bucketsort for that would take O(n nk).
- Making it better (RadixSort)
- Write the keys on base n. We have numbers of k
ciphers - Run k times the BucketSort algorithm sorting the
objects according to each cipher, in order,
starting from the less significant cipher
(last?)until the most significant one (first?)
(e.g. using mod and div). - cost O(kn).
8
Example for RadixSort
- n10, k2.
- Sequence to be sorted
- 64, 17, 3, 99, 79, 78, 19, 13, 67, 34.
- 1. step insert them in buckets according to the
last cipher - after that, output them in the order they are
- 3, 13, 64, 34, 17, 67, 78, 99, 79, 19
0 1 2 3 4 5 6 7 8 9
3 13 64 34 17 67 78 99 79 19
9
Continuation RadixSort
- 2nd. step the sequence obtained from the step 1
- 3, 13, 64, 34, 17, 67, 78, 99, 79, 19
- Insert in the buckets according to the
penultimate cipher - and output them
- 3, 13, 17, 19, 34, 64, 67, 78, 79, 99.
0 1 2 3 4 5 6 7 8 9
3 13 17 19 34 64 67 78 79 99
10
Generalizing
- Ciphers in different possitions can have a
different value range. - Example Date(year, month, day)
- ( 0..9999, 1..12, 1..31 )
- BucketSort the dates according to day, month and
year.
11
General things about binary trees
- They are recursive structures, this means, many
algorithms over them are better (shorter, more
elegant) expressed in a recursive way - This means, in most cases it is necessary to
execute recursively the algorithm on one or both
sub-trees and analyze the root node (the order
may vary according to the task) - (one of) The base case(s) (when there is no
recursive call any more) is when the pointer to
the root of the - (sub-)tree is null (empty tree)
- To improve efficiency we can avoid recursive
calls when there is no child
12
Example 1 search
Node search(int x, Node y) //returns a
pointer to the node containing y //null if it
is not in the tree if (y null) return
null if (y.key x) return y if (y.key
gt x) return search(x, y.left) return
search(x, y.right)
13
Exmple 2 count
int count(Node y) //returns the number of
nodes in the tree if (y null) return 0
int a count(y.right) int b
count(y.left) return a b 1 //
return count(y.right)count(y.left)1
14
Exmple 3 check if search tree
boolean isBST(Node y) //returns true if the
tree is a //binary search tree if (y
null) return true if (y.right null
y.left null) return true if
(!isBST(y.left) !isBST(y.right))
return false if (y.left ! null
max(y.left) lt y.key y.right ! null
min(y.right) gt y.key) return true
return false
15
Exmple 3 more effienciently
class Resp int min, max boolean ok
Resp(int x, int y, boolean z) min x max y
ok z resp isBST(Node y) if (y
null) return new Resp(0,0,true) Resp a
null, b null c new Resp(y.key, y.key,
true) if (y.left ! null) a
isBST(y.left) if (y.right ! null) b
isBST(y.right) if ( a ! null b ! null)
c.min a.min c.max b.max c.ok
a.ok b.ok a.max lt y.key b.min gt y.key
if (a ! null b null) c.min
a.min c.ok a.ok a.max lt y.key if ( a
null b ! null) c.max b.max c.ok
b.ok b.min gt y.key return c
16
Chapter 7 Selected Algorithms
- 7.1 External Search
17
7.1 External Search
- The algorithms we have seen so far are good when
all data are stored in primary storage device
(RAM). Its access is fast(er) - Big data sets are frequently stored in secondary
storage devices (hard disk). Slow(er) access
(about 100-1000 times slower) - Access always to a complete block (page) of
data (4096 bytes), which is stored in the RAM - For efficiency keep the number of accesses to
the pages low!
18
- For external search a variant of search trees
- 1 node 1 page
- Multiple way search trees!
19
- Definition (Multiple way-search trees)
- An empty tree is a multiple way search tree with
an empty set of keys . - Be T0, ..., Tn multiple way-search trees with
keys taken from a common key set S, and be
k1,...,kn a sequence of keys with k1 lt ...lt kn.
Then is the sequence - T0 k1 T1 k2 T2 k3 .... kn Tn
- a multiple way-search trees only when
- for all keys x from T0 x lt k1
- for i1,...,n-1, for all keys x in Ti, ki lt x lt
ki1 - for all keys x from Tn kn lt x
20
B-Tree
- Definition 7.1.2
- A B-Tree of Order m is a multiple way tree with
the following characteristics - 1 ? (keys in the root) ? 2m and
- m ? (keys in the nodes) ? 2m
- for all other nodes.
- All paths from the root to a leaf are equally
long. - Each internal node (not leaf) which has s keys
has exactly s1 children.
21
Example a B-tree of order 2
22
Assessment of B-trees
- The minimal possible number of nodes in a B-tree
of order m and height h - Number of nodes in each sub-tree
- 1 (m1) (m1)2 .... (m1)h-1
- ( (m1)h 1) / m.
- The root of the minimal tree has only one key and
two children, all other nodes have m keys. - Altogether number of keys n in a B-tree of
height h - n ? 2 (m1)h 1
- Thus the following holds for each B-tree of
height h with n keys - h ? logm1 ((n1)/2) .
23
Example
- The following holds for each B-tree of height h
with n keys - h ? logm1 ((n1)/2).
- Example for
- Page size 1 KByte and
- each entry plus pointer 8 bytes,
- If we chose m63, and for an ammount of data of
- n 1 000 000
- We have h ? log 64 500 000.5 lt 4 and with
that hmax 3.
24
Algorithms for searching keys in a B-tree
- Algorithm search(r, x)
- //search for key x in the tree having as root
node r - //global variable p
- in r, search for the first key y gt x or
until no more keys - if y x stop search, p r, found
- else
- if r a leaf stop search, p r, not found
- else
- if not past last key search(pointer to
node before y, x) - else search(last pointer, x)
25
Algorithms for inserting and deleting of keys in
a B-tree
- Algorithm insert (r, x)
- //insert key x in the tree having root r
- search for x in tree having root r
- if x was not found
- be p the leaf where the search stopped
- insert x in the right position
- if p now has 2m1 keys
- overflow(p)
26
Algorithm Split (1)
- Algorithm
- overflow (p) split (p)
- Algorithm split (p)
- first case p has a parent q.
- Divide the overflowed node. The key of the middle
goes to the parent. - remark the splitting may go up until the root,
in which case the height of the tree is
incremented by one.
27
Algorithm Split (2)
- Algorithm split (p)
- second case p is the root.
- Divide overflowed node. Open a new level above
containing a new root with the key of the middle
(root has one key).
28
Algorithm delete (r,x)
- //delete key x from tree having root r
- search for x in the tree with root r
- if x found
- if x is in an internal node
- exchange x with the next bigger key x' in
the tree - // if x is in an internal node then there
must - // be at least one bigger number in the
tree - //this number is in a leaf !
- be p the leaf, containing x
- erase x from p
- if p is not in the root r
- if p has m-1 keys
- underflow (p)
29
Algorithm underflow (p)
- if p has a neighboring node with sgtm nodes
- balance (p,p')
- else
- // because p cannot be the root, p must
have a neighbor with m keys - be p' the neighbor with m keys merge
(p,p')
30
Algorithm balance (p, p') // balance node p with
its neighbor p' (s gt m , r ?(ms)/2? -m )
31
Algorithm merge (p,p') // merge node p with its
neighbor perform the following operation
- afterwards
- if( q ltgt root) and (q has m-1 keys) underflow
(q) - else (if(q root) and (q empty)) free q let root
point to p
32
Recursion
- If when performing underflow we have to perform
merge, we might have to perform underflow again
one level up - This process might be repeated until the root.
33
ExampleB-Tree of order 2 (m 2)
34
Cost
- Be m the order of the B-tree,
- n the number of keys.
- Costs for search , insert and delete
- O(h) O(logm1 ((n1)/2) )
- O(logm1(n)).
35
Remark
- B-trees can also be used as internal storage
structure - Especially B-trees of order 1
- (then only one or 2 keys in each node
- no elaborate search inside the nodes).
- Cost of search, insert, delete
- O(log n).
36
Remark use of storage memory
- Over 50
- reason the condition
- 1/2k ? (keys in the node) ? k
- For nodes ? root
- (k2m)
37
- Even higher usage ratio of memory is possible to
achieve with the following condition ( 66) - 2/3k ? (keys in nodes) ? k
- For all nodes and their children
- This can be reached by 1) modified balancing also
when inserting 2) split only then, when 2
neighbors are full. - Drawback More frequent reorganization is
necessary when inserting and deleting. - .
38
7.2 External Sorting
- Problem Sorting big amount of data, as in
external searching, stored in blocks (pages). - efficiency number of the access to pages should
be kept low! - Strategy Sorting algorithm which processes the
data sequentially (no frequent page exchanges)
MergeSort!
39
- Start n data in a file g1,
- divided in pages of size b
- Page 1 s1,,sb
- Page 2 sb1,s2b
- Page k s(k-1)b1 ,,sn
- ( k n/b )
- When sequentially processed only k page accesses
instead of n.
40
Variation of MergeSort for external sorting
- MergeSort Divide-and-Conquer-Algorithm
- for external sorting without divide-step,
- only merge.
- Definition run ordered subsequence within a
file. - Strategy by merging increasingly generated runs
until everything is sorted.
41
Algorithm
- 1. Step Generate from the sequence in the input
file g1 - starting runs and distribute them in two
files f1 and f2, - with the same number of runs (?1) in each.
- (for this there are many strategies, later).
- Now use four files f1, f2, g1, g2.
42
- 2. Step (main step)
- While the number of runs gt 1 repeat
- Merge each two runs from f1 and f2 to a double
sized run alternating to g1 und g2, until there
are no more runs in f1 and f2. - Merge each two runs from g1 and g2 to a double
sized run alternating to f1 and f2, until there
are no more runs in g1 und g2. - Each loop two phases
Recommended
