
Backend - PowerPoint PPT Presentation
1 / 1
Title:
Backend
Description:
Streamed VM. Threaded VM. Imagine. RISC CPU. VM-to-Architecture Compiler. M3T/Cyclops. Compiler ... Streaming. Native mode for M3T/Cyclops. GNU -- C/C /Fortran ... – PowerPoint PPT presentation
Number of Views:269
Avg rating:3.0/5.0
Title: Backend
1
Morphable Multithreaded Memory Tiles (M3T) Josep
Torrellas (University of Illinois at
Urbana-Champaign) Ben Abbott (Southwest
Research Institute) Ted Bapty (Vanderbilt
University) Bob Bassett, David Ngo (BAE
SYSTEMS) Hubertus Franke, Jose Moreira(IBM
Research)
Templates
Impact
New Ideas
- Provide routines required by application
- Use
- generic threads, C, C,
- specialized (possibly architecture specific)
Brook, StreamIt, StreamC/KernelC, assembly - MPI?, Corba?
- Influenced IBM CyclopsE chip with polymorphic
support - Sped up Sphinx speech processing about 2.5x
through polymorphism - Estimated 60x reduction in size, weight, and
power per speech channel - Estimated 20x reduction in cost per speech
channel
- M3T morphs into VLIW, MIMD and TaskScalar
templates - Polymorphism at every stage of the system
- M3T morphs on demand within application
Hand coded versions of classic algorithms for
various templates
Problem Specifications
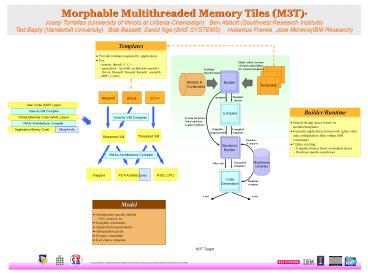
Models Constraints
Builder
Templates
StreamIt
Brook
C/C
Template chosen
pragmas
User Code (SAPI Layer)
Builder/Runtime
User-to-VM Compiler
Compiler
User-to-VM Compiler
Virtual Machine Code (SAAL Layer)
System Structure (what and how to glue together)
- Search design space based on models/templates
- Generate application framework (glue code)
and configuration files within MSI - constraints
- Utilize existing
- Compilers/linkers based on template choice
- Hardware specific morphware
VM-to-Architecture Compiler
Template requirements
Application Binary Code
Morph Info
Compiled template
Threaded VM
Streamed VM
Headers macros
Backend Builder
Streaming
VM-to-Architecture Compiler
- Native mode for M3T/Cyclops
- GNU -- C/C/Fortran
- Augmentation with superscalar possible
- MPI, Corba possible (not currently supported)
Morphware Libraries
Expanded templates
Glue code
Imagine
RISC CPU
PCA Architectures
Code Generation
Compiler
Runtime routines
M3T/Cyclops
- Transformation based on three templates
- MIMD, TaskScalar, VLIW
- Target to two morphable architectures
- M3T, Cyclops
- Support automatic and manual parallelization
Threaded
a.out
a.out
Model
- Use cache interest group coding as routing
network - Support SIMD via fast barrier
- Utilize thread units as imagine clusters
- Compiler/macro/template support needed
- Architecture specific details
- - ALU, memory, etc.
- Template constraints
- Application requirements
- Optimization goals
- System constraints
- Tool choice structure
M3T Target
Cyclops Target
Some parts adapted from The Stanford Smart
Memories Compilation Framework, Ian Buck,
François Labonte, Lance Hammond, Stanford
University, Morphware Forum 4, April 2002
Recommended
CrystalGraphics Presentations





























