
Multitasking. Segmentare - PowerPoint PPT Presentation
1 / 23
Title:
Multitasking. Segmentare
Description:
Title: Procesoarele 386/ 486/ Pentium. Multitasking. Author: Vasile Lungu Last modified by: Vasile Lungu Created Date: 10/4/2004 2:36:42 PM Document presentation format – PowerPoint PPT presentation
Number of Views:141
Avg rating:3.0/5.0
Title: Multitasking. Segmentare
1
Multitasking. Segmentare
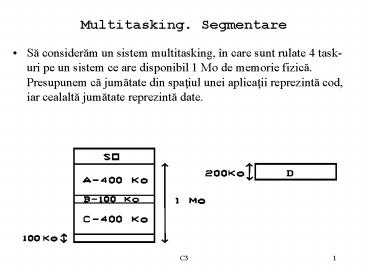
- Sa consideram un sistem multitasking, în care
sunt rulate 4 task-uri pe un sistem ce are
disponibil 1 Mo de memorie fizica. Presupunem ca
jumatate din spatiul unei aplicatii reprezinta
cod, iar cealalta jumatate reprezinta date.
2
- Planificatorul SO începe executia task-ului A
milisecunde, apoi permite executia task-ului B,
tot pentru câteva milisecunde. Totusi, pe durata
alocata, task-ul B citeste o intrare, a
operatorului, de la tastatura daca nici o tasta
nu a fost apasata, SO ia controlul si marcheaza
task-ul B ca fiind suspendat. Apoi planificatorul
da controlul task-ului C, pe durata de timp
alocata, dupa care se va transfera controlul
task-ului D. Acesta începe executia, dar imediat
ce încearca referirea segmentului de date,
procesorul genereaza întreruperea non-prezent
(NP). - SO va determina ca taskul D necesita acces la
segmentul sau de date -gt evalueaza starile
celorlalte task-uri. Întrucât task-ul B este
suspendat, SO decide sa-l înlocuiasca temporar
din memorie pentru a face loc pentru segmentul de
date al task-ului D. - Imaginea din memorie a lui B este scrisa pe disc
si descriptorul pentru B este marcat ca NP
task-ul B a fost scos (swapped out), si SO care
implementeaza memoria virtuala într-o astfel de
maniera, implementeaza interschimbarea (swapping).
3
(No Transcript)
4
- Planificatorul comuta timpul de executie între A,
C si D. - La un moment dat operatorul, care vede promptul,
pentru intrarea de la task-ul B, va apasa o tasta
-gt întrerupere hard, si SO trebuie sa planifice
task-ul B. Deoarece nici unul dintre celelalte
task-uri nu este suspendat, SO alege sa suspende
temporar un task (A). Deoarece task-ul B este
mic, el înlocuieste o parte din A (cod). Seg. cod
A este marcat ca NP, task-ul B este
interschimbat, si descriptorii pentru task-urile
A si B sunt modif. corespunzator. - Task-ul B ruleaza acum la o adresa fizica
diferita decât când a început. - SO poate interschimba segmente, bazându-se fie pe
ce task a rulat cel mai mult, fie pe un alt
sistem de prioritati. - Cu cât timpul de interschimbare este mai mare, cu
atât este mai mic timpul pentru executia
aplicatiilor. - Întrucât seg. de cod sunt nemodificabile -gt nu
trebuie salv. Disc, deci SO intersch. de 2 mai
rapid cod fata de date (pot fi si ele marcate ca
read-only si atunci nici ele nu trebuie salvate).
5
(No Transcript)
6
- Alta facilitate se refera la tehnica partajarii
segmentului care permite ca doua sau mai multe
task-uri sa partajeze acelasi cod. (sisteme
multiutilizator). - Sa presupunem, în ex. anterior, ca task-urile A,
B, C si D reprezinta utilizatori ce ruleaza
aplicatii. Sa presupunem ca utilizatorii A si C
ruleaza aceeasi aplicatie (o foaie de calcul). A
si C, opereaza pe date diferite si necesita
segmente de date separate, dar executa acelasi
cod. Utilizatorii pastreaza descriptori separati
pentru codurile si datele lor, dar adresele de
baza pentru segmentele de cod, pentru A si C
refera aceeasi locatie. - De asemenea, un sistem de MV, orientat pe
segmente, poate furniza un mod pentru a compacta
memoria. Compactarea memoriei permite rezolvarea
unei probleme numite fragmentare. Fragmentarea
memoriei apare când memoria ce nu este continua
este disponibila pentru a rula aplicatii
suplimentare. - Un alt avantaj al MV este eliminarea
constrângerilor, datorate memoriei, pentru
programele ce lucreaza cu zone mari de memorie.
7
(No Transcript)
8
- Paginarea si administrarea memoriei cache
- Paginarea este utilizata pentru a implementa MV
bazata pe blocuri de dimensiune fixa, pagini.
Asemanator segmentarii, paginarea translateaza
adresele virtuale în adrese fizice, prin maparea
(suprapunerea) blocurilor de lungime fixa, de
memorie, în locatiile de memorie fizica, denumite
cadru pagina. Segmentarea si paginarea sunt
similare un nume si un offset sunt translatate
într-o adresa.
9
- Avantajul esential al paginarii fata de
segmentare este reprezentat de dimensiunea fixa a
paginarii. Deoarece MV utilizeaza discul se pot
alege dimensiuni de pagina care se potrivesc cu
dimensiunea sectorului de pe disc. De asemenea
paginarea evita problema fragmentarii memoriei,
specifica segmentarii. Ori de câte ori o pagina
este scoasa din memorie, alta pagina se
potriveste exact în spatiul eliberat (apare alt
tip denumit fragmentare interna). - Alt avantaj alocarea pentru un obiect mare nu
trebuie sa fie facuta într-un spatiu continuu de
memorie. - Pagina poate contine portiuni din mai multe
segmente, sau invers.
10
- Cache-ul intern
- Performanta unui calculator este determinata, în
principal, de trei elemente procesorul, memoria
si placa de baza. - Memoria cache are rolul de a scurta acest drum al
informatiei. Ea stocheaza datele astfel încât
procesorul le poate accesa mult mai rapid. - Memoria cache memoreaza instructiuni si date,
recent accesate, astfel încât ele sunt furnizate
transparent si mai rapid decât memoria
principala. Cahe-ul este organizata pe linii.
Aceste linii sunt organizate ca seturi, fiecare
set este mapat pe un grup separat de adrese de
memorie, si care sunt de obicei între 16 si 64
linii pe set. - Programele tipice acceseaza aceleasi locatii de
memorie, în mod repetat, sau acceseaza locatii
adiacente de memorie. Numele tehnic dat acestui
fenomen este localizare temporala si respectiv
spatiala a referintei.
11
(No Transcript)
12
- Arhitectura procesorului 80386
13
- Arhitectura procesorului 80486
- Noi facilitati de executie paralela, prin
expandarea unitatilor de decodificare si executie
instructiuni, într-o banda de asamblare cu cinci
nivele (stagii), fiecare nivel opereaza în
paralel cu celelalte, (5 instr. în diferite
stagii de executie, pe un interval de ceas). - Fata de 386 contine UE în virgula mobila, cache,
coada de instr. are 32 octeti (dubla).
14
- Procesoarele Pentium includ o serie de concepte
noi - Banda de asamblare (pipeline) mai multe
instructiuni masina sunt încarcate secvential
într-o linie complexa de prelucrare, asemanatoare
cu memoria FIFO (în locul celulelor de memorie,
aici sunt automate secventiale, care efectueaza
diferite modificari asupra datelor ce trec prin
pipeline) sau cu o banda de asamblare. Prin
pipeline se sparg (translateaza) instructiunile
în micro-operatii ce se executa în unitati
separate. Rezultatul este 'asamblat' si se
trimite exteriorului. Daca s-au încarcat date
incorecte în structurile secventiale ale
pipelineului (de ex. la executia speculativa
ultimul salt a fost gresit) atunci pipeline-ul
este golit si reîncarcat cu date corecte deci el
contine toate operatiile / rezultatele ce se
executa, în acel moment, în diferite stadii, în
functie de pozitia lor în structura secventiala a
pipeline-ului. - Superscalar procesoare cu mai multe benzi de
asamblare, paralele, care pot executa mai multe
instructiuni simultan, într-un singur tact
(Pentium are doua benzi, U si V).
15
- Superbanda de asamblare procesorul poate diviza
executia fiecarei instructiuni în 12 (10) etape
(nivele), ce include, printre altele, etapele de
citire instructiune, decodificare, executie si
extragere. O instructiune înseamna mai multe
operatii (etape de prelucrare). Mai multe
instructiuni sunt suprapuse la executie diferiti
pasi (etape) de executie ale unor instructiuni
diferite sunt realizate în acelasi ciclu
procesor. - Executie dinamica (dynamic execution) se
sparge codul operatiei în mai multe
micro-operatii de lungime fixa, care dupa o
aranjare corespunzatoare se executa simultan,
într-un singur tact. - Predictia ramificatiilor multiple (sau în
adâncime), prin care procesorul anticipeaza un
numar de pasi pentru a anticipa ce urmeaza sa
prelucreze. Utilizând predictia instructiunile de
pe o ramura a programului sunt executate înainte
de cunoasterea rezultatului instructiunii de pe
de ramificatie respectiva.
16
- Analiza fluxului de date, care consta în analiza
dependentelor între instructiuni, si - Executie speculativa, care utilizeaza rezultatele
primelor doua elemente pentru a executa
speculativ instructiuni. Este o tehnica folosita
pentru a micsora impactul hazardurilor de
control, adica dependentele produse de salturi.
Arhitectura procesoarelor decupleaza distributia
si executia instructiunilor de furnizarea
rezultatelor. - Executie în orice ordine (Out of Order
Execution) executie în paralel, a
instructiunilor, fara a tine cont de ordinea lor
secventiala. Un procesor superscalar poate
executa, în paralel, mai multe instructiuni daca
exista un conflict de resurse la executia în
paralel a doua instructiuni succesive, procesorul
va executa instructiunea urmatoare, care nu intra
în conflict cu prima, urmând ca ulterior sa
revina la instructiunea peste care a sarit.
Starile conflictuale se pot rezolva si prin
redenumirea resurselor.
17
- De exemplu sa consideram urmatorul cod
- 1 add r1, r2 -gt r7
- 2 sub r7, r3 -gt r3
- 3 add r4, r5 -gt r7
- 4 sub r7, r6-gtr6
- Instructiunile 1 si 3 pot fi executate în
paralel, daca r7 este redenumit, iar
instructiunile 2 si 4 pot fi executate în
paralel. Instructiunea 3 este executata înaintea
instructiunii 2, si nu în ordinea în care apar
ele în program. - Dependente este vorba despre dependentele dintre
instructiuni. Pentru a detecta dependentele este
necesar hard suplimentar (în procesor), adica o
serie de comparatoare, care, de exemplu, compara
registrul, în care scrie o instructiune, ce se
afla în etapa (nivelul) 4, cu registrele citite
de instructiunile de pe nivelurile 3, 2. Daca
instructiunea de pe nivelul 4 va scrie în
registrul utilizat de instructiunea din nivelul
2, atunci nivelul 2 este blocat, iar 3 si 4
avanseaza, iar în nivelul 3 se formeaza o bula
(gol).
18
- Înaintarea daca, de exemplu, o instructiune
aflata în nivelul de decodificare, are nevoie de
niste date, pe care instructiunea aflata în
nivelul de executie tocmai le calculase, cea din
etapa de decodificare ar trebui sa astepte ca
rezultatul calculelor sa fie pus într-un
registru, ceea ce se va întâmpla abia mai târziu.
În astfel de situatii, însa, deoarece avem deja
rezultatul necesar, acesta poate fi trimis de la
producator direct la consumator, fara a mai
astepta sa-l scrie într-un registru. Aceasta
tehnica se numeste înaintare (forward), si ea
permite instructiunii din etapa de decodificare
sa-si continue executia, fara a se mai introduce
o bula (nop).
19
- Sistemul de întreruperi
20
(No Transcript)
21
- Întreruperi în modul protejat
- Sunt permise, în tabela IDT, doar trei tipuri de
porti întrerupere (interrupt gate), capcana
(trap gate) si task (task gate). Primele doua
prelucreaza întreruperile în cadrul aceluiasi
task, în timp ce cea de-a treia realizeaza o
comutare de task. Diferenta dintre primele doua
este ca prima pune indicatorul IF pe zero
(dezactiveaza întreruperile), în timp ce cea de-a
doua lasa indicatorul nemodificat. - Întreruperi suplimentare 8 (Double Fault), 10
(TSS invalid), 11 (NP), 12 (eroare stiva), 13
(GP), 14 (PG), si 17 (AC).
22
(No Transcript)
23
(No Transcript)
Recommended
CrystalGraphics Presentations





























![READ[PDF] Veterinary Pathologist Only Because Multitasking N PowerPoint PPT Presentation](https://s3.amazonaws.com/images.powershow.com/10083696.th0.jpg?_=20240723076)