
Prsentation PowerPoint - PowerPoint PPT Presentation
1 / 12
Title:
Prsentation PowerPoint
Description:
A L2 memory address is divided into 3 regions to select its appropriate L1D ... needs to take care of which data is loaded, from which address and in what order. ... – PowerPoint PPT presentation
Number of Views:97
Avg rating:3.0/5.0
Title: Prsentation PowerPoint
1
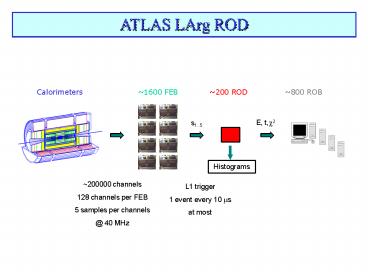
ATLAS LArg ROD
Calorimeters
1600 FEB
200 ROD
800 ROB
E, t,?2
s1..5
Histograms
200000 channels 128 channels per FEB 5 samples
per channels _at_ 40 MHz
L1 trigger 1 event every 10 ?s at most
2
ROD daughter boards (PU)
ROD board
1 ROD board has 4 PU hence 8 DSP
PU1
FEB 8 G-Link
ROB 4 S-Link
PU2
PU3
PU4
PU board
64 bit
16 bit
FI FO
DSP
Input FPGA
FEB116 bit
DSP Le cur du calcul FPGA d'entrée
convertisseur série / parallèle. Peut faciliter
la tache du DSP en modifiant le formatage des
données.
16 bit
Output FPGA
VME
TTC
FI FO
DSP
Input FPGA
FEB216 bit
16 bit
64 bit
16 bit
3
ROD Physics Use-Case
in
out
ROD
DSP pour 128 canaux par événements Calcul de
E ou E, t, ?2
Input FPGA données en // au format DSP
Données d'entrée données en série au format
FEB
Données de sortie E entier 16 bit ou E
entier 16 bit t, ?2 et gain 32 bit ou E 32
bit t, ?2 et gain 32 bit
Output FPGA données TTC
Histogrammes
interface VME
Partie "programmable "
Astreintes
4
Le DSP TMS320C6414
2 bus d'entrée (64 et 16 bit) 1 MB de mémoire
L2 2x16 KB de mémoire cache L1 2x32 registres de
32 bits 2x4 unités de calcul opérant en // L
arithmétique et comparaison S arithmétique,
arithmétique binaire et branchements M
multiplication D arithmétique, adresses et accès
mémoire
program cache L1P / program memory L2 32 bit
address - 256 bit data (8x32 bit)
program fetch
control registers control logic test emulation in
terrupts
instruction dispatch
instruction decode
16 bit
DMA EMIFA, EMIFB
data path A X data path B
32 registers
32 registers
64 bit
L1
S1
M1
D1
D2
M2
S2
L2
data cache L1D / data memory L2 32 bit address
8, 16, 32 or 64 bit data
timers, serial ports,
fréquence de fonctionnement 600 MHz (cur et
L1) et 100 MHz (L2)
5
Ecriture de l'algorithme
Exemple calcul de l'énergie d'une cellule
E?ai(si-p)
ldw sptr,s1
ldw sptr,s23
ldw sptr,s45 shru s1,16,gain
add aptr,gain,axptr
add 16,aptr,aptr lddw axptr
,a23a45 lddw axptr,pxa1
chargement des données extraction du
gain chargement des poids ai
8
a1s1
a2s2a2s2
a5s5a5s5
?aisi (i2..5)
?aisi (i1..5)
E?aisi-?aip
mpy s1,a1,sa1 dotp2 a23,s23,sa23 dotp2 s45,a45,s
a45 add sa23,sa45,sa25 add sa1,sa25,sa15 sub
sa15,px,e
6
extraction de l'énergie en unités de 1/216
GeV sauvegarde des résultats et cellule suivante
shru a1,16,n shr e,n,short_e cmpgt
short_e,th,ok
ok stdw celle,data
ok add sweet,1,sweet
!ok
sth short_e,results_e add cell,2,cell
bdec label,compteur
8
6
Optimisation de l'algorithme
L'optimisation est effectuée automatiquement par
le compilateur
SOFTWARE PIPELINE INFORMATION Known
Minimum Trip Count 64 Known
Maximum Trip Count 64
128 cellules avec 2 cellules par itération
Resource Partition
A-side B-side .L units
1 1 .S units
5 2 .D units
8 8 .M units
4 2 .X cross paths
5 8 .T address paths
8 6 Long read paths
0 0 Long write paths
0 0 Logical ops (.LS)
0 1 Addition ops (.LSD)
7 9 Bound(.L .S .LS) 3
2 Bound(.L .S .D .LS .LSD) 8
8
nb d'instructions à répartir sur .L1
Analyse
nb d'instructions à répartir sur .L2 ou .S2
nb min de cycles pour la boucle
Searching for software pipeline schedule
ii 8 Schedule found with 5
iterations in parallel Epilog not
removed 27 cycles Prolog not
removed 28 cycles Minimum safe
trip count 5
Résultats
Nombre total de cycles pour 128 canaux
278/212828 567 4.4 128
7
L'algorithme de calcul de Physique
L'algorithme est découpé en 3 boucles
Boucle 1 (pour les 128 canaux) E?ai(si-p) n
nombre de cellules avec EgtE0
567 cycles pour la boucle 11 cycles d'appel à la
fonction 4.5 cycles/canal
Boucle 2 (pour les n canaux) t1/E
?bi(si-p) ?2?(si-p-Ehi)2
1325 cycles pour la boucle 11 cycles d'appel à
la fonction 10.4 cycles/canal
Boucle 3 (pour les n canaux) Histogrammes de
E, t, ?2 dans les différents gains
1314 cycles pour la boucle 11 cycles d'appel à
la fonction 10.4 cycles/canal
Soit pour une fraction f de cellules d'énergie
EgtE0 nb cycles 128 (4.5 f 20.8) pour f
10 on a 1286.6 844 cycles
8
La mémoire cache
Pour une fraction f de cellules d'énergie EgtE0,
on a obtenu nb cycles 128 (4.5 f
20.8) Il s'agit là de cycles d'instructions ! En
effet la différence de fréquence de
fonctionnement entre le CPU (600 MHz) et la
mémoire L2 (100 MHz) induit des cycles d'attente
lors des accès mémoire.
Normalement 6 cycles d'attente par lecture Pour
l'énergie, nous avons 6 opérations de lecture par
canal
66 36 cycles d'attente soit 4.536 40.5
cycles/canal !
Il faut donc comprendre le fonctionnement de la
mémoire cache pour améliorer ces chiffres.
9
Level 1 data cache (L1D)
A L2 memory address is divided into 3 regions to
select its appropriate L1D location
bits 5 to 0 byte offset
bits 12 to 6 set index
bits 31 to 13 tag
6 bits 0 to 3F
7 bits 0 to 7F
19 bits
Each access to a L2 data cause a whole 64 byte
line to be loaded in L1D
Each set is made of 2 lines
L2 memory 1024 KB
L1D memory 16 KB128 sets2 lines of 64 bytes
set
line
adresse (hex)
00
00
00
00000 02004 0403F 04040 0407F 04080 040BF 01FC0
FFFFF
0 0 0 1 1 2 2 127 127
0 or 1 0 or 1 0 or 1 0 or 1 0 or 1 0 or 1 0 or
1 0 or 1 0 or 1
04
00
01
3F
00
02
00
01
02
3F
01
02
00
02
02
3F
02
02
00
7F
00
3F
7F
FD
10
Level 1 data cache (L1D)
0) Definitions
MISS Any attempt to load L2 data which are not
already in L1D STALL The number of cycles
needed to load data from L2 to L1D
1) L1D Mapping
To reduce the number of miss one needs to take
care of which data is loaded, from which address
and in what order.
2) L1D Pipelining
To reduce the number of stalls one can use miss
pipelining for consecutive loads
11
L1D access optimisation
Studied strategies samples preloading
maximize miss pipelining no samples preloading
less miss pipelining but also less
instructions raw histograms
standard organisation for histograms in
memory interleaved histograms cache-friendly
organisation for histograms in memory
with f0 to 20
12
Results
Total processing time _at_ 600 MHz
Simulated (left plot) with only physics code lt
4 ?s _at_ 600 MHz for f20 and 5
histograms Measured with RTXsynchronisation
task 5.8 ?s _at_ 480 MHz for f17 and 5
histograms extrapolated to 5.0 ?s _at_ 600 MHz
for f20 and 5 histograms
Recommended
CrystalGraphics Presentations





























