
SFM under orthographic projection - PowerPoint PPT Presentation
Title:
SFM under orthographic projection
Description:
... face detection Here, X is an image region dimension = # pixels each face can be thought of as a point in a high dimensional space H. Schneiderman, ... – PowerPoint PPT presentation
Number of Views:141
Avg rating:3.0/5.0
Title: SFM under orthographic projection
1
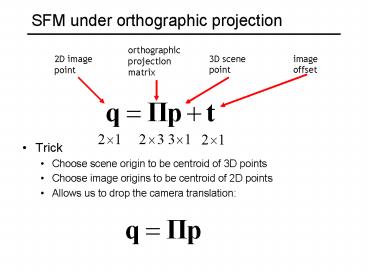
SFM under orthographic projection
orthographic projection matrix
3D scene point
image offset
2D image point
- Trick
- Choose scene origin to be centroid of 3D points
- Choose image origins to be centroid of 2D points
- Allows us to drop the camera translation
2
factorization (Tomasi Kanade)
projection of n features in one image
3
Factorization
4
Metric constraints
- Orthographic Camera
- Rows of P are orthonormal
- Enforcing Metric Constraints
- Compute A such that rows of M have these
properties
5
Results
6
Extensions to factorization methods
- Paraperspective Poelman Kanade, PAMI 97
- Sequential Factorization Morita Kanade, PAMI
97 - Factorization under perspective Christy
Horaud, PAMI 96 Sturm Triggs, ECCV 96 - Factorization with Uncertainty Anandan Irani,
IJCV 2002
7
Bundle adjustment
8
Structure from motion
- How many points do we need to match?
- 2 frames
- (R,t) 5 dof 3n point locations ?
- 4n point measurements ?
- n ? 5
- k frames
- 6(k1)-1 3n ? 2kn
- always want to use many more
9
Bundle Adjustment
- What makes this non-linear minimization hard?
- many more parameters potentially slow
- poorer conditioning (high correlation)
- potentially lots of outliers
10
Lots of parameters sparsity
- Only a few entries in Jacobian are non-zero
11
Robust error models
- Outlier rejection
- use robust penalty appliedto each set of
jointmeasurements - for extremely bad data, use random sampling
RANSAC, Fischler Bolles, CACM81
12
Correspondences
- Can refine feature matching after a structure and
motion estimate has been produced - decide which ones obey the epipolar geometry
- decide which ones are geometrically consistent
- (optional) iterate between correspondences and
SfM estimates using MCMCDellaert et al.,
Machine Learning 2003
13
Structure from motion limitations
- Very difficult to reliably estimate
metricstructure and motion unless - large (x or y) rotation or
- large field of view and depth variation
- Camera calibration important for Euclidean
reconstructions - Need good feature tracker
- Lens distortion
14
Issues in SFM
- Track lifetime
- Nonlinear lens distortion
- Prior knowledge and scene constraints
- Multiple motions
15
Track lifetime
- every 50th frame of a 800-frame sequence
16
Track lifetime
- lifetime of 3192 tracks from the previous sequence
17
Track lifetime
- track length histogram
18
Nonlinear lens distortion
19
Nonlinear lens distortion
- effect of lens distortion
20
Prior knowledge and scene constraints
- add a constraint that several lines are parallel
21
Prior knowledge and scene constraints
- add a constraint that it is a turntable sequence
22
Applications of Structure from Motion
23
Jurassic park
24
PhotoSynth
http//labs.live.com/photosynth/
25
So far focused on 3D modeling
- Multi-Frame Structure from Motion
- Multi-View Stereo
Unknown camera viewpoints
26
Next
- Recognition
27
Today
- Recognition
28
Recognition problems
- What is it?
- Object detection
- Who is it?
- Recognizing identity
- What are they doing?
- Activities
- All of these are classification problems
- Choose one class from a list of possible
candidates
29
How do human do recognition?
- We dont completely know yet
- But we have some experimental observations.
30
Observation 1
31
Observation 1
The Margaret Thatcher Illusion, by Peter
Thompson
32
Observation 1
The Margaret Thatcher Illusion, by Peter
Thompson
- http//www.wjh.harvard.edu/lombrozo/home/illusion
s/thatcher.htmlbottom - Human process up-side-down images separately
33
Observation 2
Kevin Costner
Jim Carrey
- High frequency information is not enough
34
Observation 3
35
Observation 3
- Negative contrast is difficult
36
Observation 4
- Image Warping is OK
37
The list goes on
- Face Recognition by Humans Nineteen Results All
Computer Vision Researchers Should Know About
http//web.mit.edu/bcs/sinha/papers/19results_sinh
a_etal.pdf
38
Face detection
- How to tell if a face is present?
39
One simple method skin detection
skin
- Skin pixels have a distinctive range of colors
- Corresponds to region(s) in RGB color space
- for visualization, only R and G components are
shown above
- Skin classifier
- A pixel X (R,G,B) is skin if it is in the skin
region
- But how to find this region?
40
Skin detection
- Learn the skin region from examples
- Manually label pixels in one or more training
images as skin or not skin - Plot the training data in RGB space
- skin pixels shown in orange, non-skin pixels
shown in blue - some skin pixels may be outside the region,
non-skin pixels inside. Why?
41
Skin classification techniques
- Skin classifier
- Given X (R,G,B) how to determine if it is
skin or not? - Nearest neighbor
- find labeled pixel closest to X
- choose the label for that pixel
- Data modeling
- fit a model (curve, surface, or volume) to each
class - Probabilistic data modeling
- fit a probability model to each class
42
Probability
- Basic probability
- X is a random variable
- P(X) is the probability that X achieves a certain
value - or
- Conditional probability P(X Y)
- probability of X given that we already know Y
- called a PDF
- probability distribution/density function
- a 2D PDF is a surface, 3D PDF is a volume
continuous X
discrete X
43
Probabilistic skin classification
- Now we can model uncertainty
- Each pixel has a probability of being skin or not
skin
- Skin classifier
- Given X (R,G,B) how to determine if it is
skin or not?
44
Learning conditional PDFs
- We can calculate P(R skin) from a set of
training images - It is simply a histogram over the pixels in the
training images - each bin Ri contains the proportion of skin
pixels with color Ri
This doesnt work as well in higher-dimensional
spaces. Why not?
45
Learning conditional PDFs
- We can calculate P(R skin) from a set of
training images - It is simply a histogram over the pixels in the
training images - each bin Ri contains the proportion of skin
pixels with color Ri
- But this isnt quite what we want
- Why not? How to determine if a pixel is skin?
- We want P(skin R) not P(R skin)
- How can we get it?
46
Bayes rule
- In terms of our problem
- The prior P(skin)
- Could use domain knowledge
- P(skin) may be larger if we know the image
contains a person - for a portrait, P(skin) may be higher for pixels
in the center - Could learn the prior from the training set. How?
- P(skin) may be proportion of skin pixels in
training set
47
Bayesian estimation
likelihood
posterior (unnormalized)
minimize probability of misclassification
- Bayesian estimation
- Goal is to choose the label (skin or skin) that
maximizes the posterior - this is called Maximum A Posteriori (MAP)
estimation
- Suppose the prior is uniform P(skin) P(skin)
0.5
48
Skin detection results
49
General classification
- This same procedure applies in more general
circumstances - More than two classes
- More than one dimension
- Example face detection
- Here, X is an image region
- dimension pixels
- each face can be thoughtof as a point in a
highdimensional space
H. Schneiderman, T. Kanade. "A Statistical Method
for 3D Object Detection Applied to Faces and
Cars". IEEE Conference on Computer Vision and
Pattern Recognition (CVPR 2000)
http//www-2.cs.cmu.edu/afs/cs.cmu.edu/user/hws/w
ww/CVPR00.pdf
Recommended
CrystalGraphics Presentations





























