
Fundamentos de programa PowerPoint PPT Presentation
Title: Fundamentos de programa
1
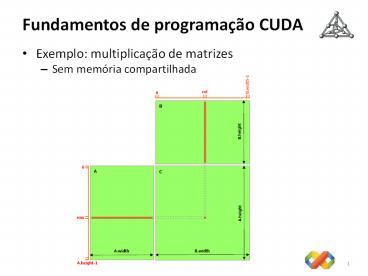
Fundamentos de programação CUDA
- Exemplo multiplicação de matrizes
- Sem memória compartilhada
2
Fundamentos de programação CUDA
- Memória compartilhada
- Disponível para threads de um mesmo bloco
- Acesso 400 a 600 mais rápido que memória global
- Permite colaboração entre threads (do bloco)
- Cada thread do bloco transfere dados da memória
global para memória compartilhada - Após a transferência, threads devem ser
sincronizadas com __syncthreads() - Kernel efetua operações usando os dados da
memória compartilhada cada thread pode usar
dados carregados por outras threads do bloco - Se necessário, threads podem ser sincronizadas
com __syncthreads() cada thread do bloco
transfere dados da memória compartilhada para
memória global
3
Fundamentos de programação CUDA
- Exemplo multiplicação de matrizes
- Com memória compartilhada
4
Fundamentos de programação CUDA
- Exemplo transposição de matrizes
Mem. compartilhada
__syncthreads()
5
Fundamentos de programação CUDA
- Exemplo transposição de matrizes
Mem. compartilhada
6
Fundamentos de programação CUDA
- Implementação em hardware
- Arquitetura arranjo de multiprocessadores (SMs)
- Cada SM consiste de
- 8 processadores (SPs)
- 1 unidade de instrução
- Memória compartilhada
- Cada SM
- Executa threads de um bloco em grupos de 32 warp
- Implementa barreira de sincronização__syncthread
s() - Emprega arquitetura SIMTSingle Instruction
Multiple Thread
7
Dicas de performance
- Estratégias básicas
- Maximização da execução em paralelo
- Estruturação do algoritmo
- Escolha da configuração de execução do kernel
- Número de threads por bloco múltiplo do tamanho
do warp - Mínimo de 64 threads por bloco
- Configuração inicial entre 128 e 256 threads por
bloco - Evitar divergência dentro do mesmo warp
- Otimização do uso de memória
- Minimização de transferência de dados
host/dispositivo - Acesso coalescido à memória global
- Uso de mem. compartilhada
- Acesso sem conflitos de bancos à mem.
compartilhada - Otimização do uso de instruções
8
Dicas de performance
- Memória global
- O dispositivo é capaz de ler palavras de 4, 8 ou
16 bytes da memória global para registradores com
UMA única instrução, DESDE que o endereço de
leitura seja alinhado a (múltiplo de) 4, 8, ou
16. - A largura de banda da memória global é mais
eficientemente usada quando acessos simultâneos à
memória por threads de um meio-warp (durante a
execução de uma instrução de leitura ou escrita)
podem ser coalescidos em uma única transação de
32, 64 ou 128 bytes de memória.
9
Dicas de performance
- Memória global
- Coalescência em dispositivos 1.0 e 1.1
- Ocorre em transação de 64 ou 128 ou duas
transações de 128 bytes - Threads de um meio-warp devem acessar
- Palavras de 4 bytes, resultando numa transação de
64 bytes, - Ou palavras de 8 bytes, resultando numa transação
de 128 bytes, - Ou palavras de 16 bytes, resultando em duas
transações de 128 bytes - Todas as 16 palavras (cada uma acessada por uma
das 16 threads do meio-warp) devem estar no mesmo
segmento de tamanho igual ao tamanho das
transações (ou seja, 64, 128 ou 256 bytes). Como
consequência, o segmento deve ser alinhado a este
tamanho - Threads devem acessar palavras na sequência a
thread k deve acessar a palavra k
10
Dicas de performance
- Memória global
- Com coalescência
11
Dicas de performance
- Memória global
- Sem coalescência
12
Dicas de performance
- Memória global
- Sem coalescência
13
Dicas de performance
- Memória global
- Coalescência com vetor de estruturas (AOS)
- Tamanho da estrutura até 16 bytes
- Alinhamento deve ser 4, 8 ou 16 bytes, dependendo
do tamanho - Elementos devem estar no mesmo segmento da
transação - Estruturas maiores que 16 bytes reorganizar em
estrutura de vetores (SOA) com elementos de
tamanho até 16 bytes
14
Dicas de performance
- Memória compartilhada
- Dividida em módulos chamados bancos
- Em dispositivos 1.x o número de bancos é 16
- Bancos tem largura de 32 bits
- Palavras sucessivas de 32 bits estão em bancos
sucessivos - Acessos a n endereços que estão em n bancos
distintos são efetuados simultaneamente - Acessos a dois endereços que estão no mesmo banco
geram um conflito de banco acessos são
serializados - Threads de um meio-warp devem acessar endereços
em bancos distintos para evitar conflitos de
bancos
15
Dicas de performance
- Mem. compartilhada
- Sem conflitos
16
Dicas de performance
- Mem. compartilhada
- Com conflitos
17
APIs para CUDA
- CUBLAS
- CUFFT
- Primitivos paralelos CUDAPP
- Algoritmos
- Redução
- Soma prefixa
- Compactação
- Ordenação
- Exemplos no SDK CUDA
- Scan
- Partículas
- Etc.
Recommended
